
Introducción a las Redes Neuronales
Las redes neuronales artificiales son un paradigma de aprendizaje y de procesamiento automatizado basado en el funcionamiento del sistema nervioso biológico, en este sentido, las redes neuronales artificiales son sistemas de procesamiento que copian esquemáticamente la estructura neuronal del cerebro con el fin de reproducir sus capacidades. Una red neuronal está conformada por un grupo de neuronas interconectadas que colaboran entre sí para producir un estímulo de salida.
De esta manera, las redes neuronales artificiales son capaces de aprender de la experiencia a partir de datos o señales provenientes del exterior en un marco de computación paralela y distribuida.
En la estructura neuronal biológica, en general, las neuronas constituyen procesadores de información sencillos. Poseen un canal de entrada de información que son las dentritas, un órgano de cómputo, que es el cuerpo celular o soma y un canal de salida que es el axón.
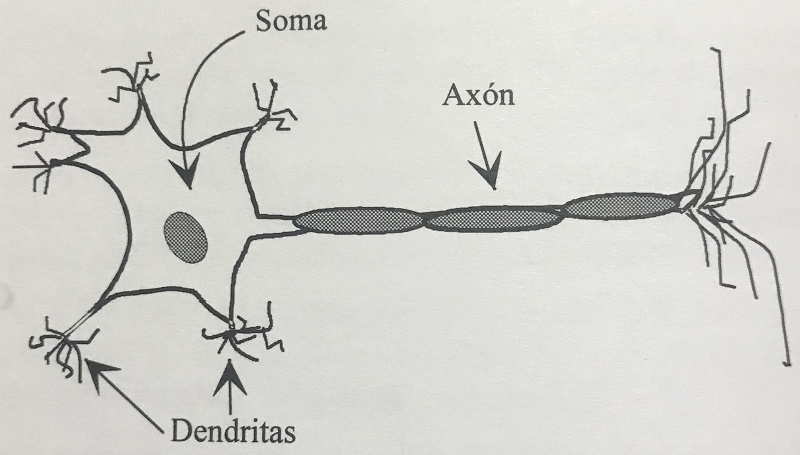
El axón envía la información a otras neuronas y si éstas últimas son motoras, la información se envía directamente al músculo. En el caso de las neuronas receptoras o sensoras, reciben la información directamente del exterior, en lugar de hacerlo desde otras neuronas.
La unión entre dos neuronas se denomina sinapsis y representa una comunicación direccional, es decir, que fluye en un sólo sentido.
Cada neurona recibe un conjunto de entradas a través de sus interconexiones y produce una salida que depende de la sinapsis realizada y del procesamiento realizado en el cuerpo de la neurona.
Análogamente, en los sistemas de redes neuronales artificiales, se imita la estructura del sistema nervioso con la intención de construir sistemas con un cierto comportamiento inteligente en un esquema de procesamiento paralelo, distribuido y adaptativo.
Cuando se dice que las redes neuronales artificiales son sistemas paralelos, distribuidos y adaptativos, es por que se intenta emular el paralelismo de cálculo, la memoria distribuida y la adaptabilidad al entorno.
Verlo en video aquí y suscribete al canal en Youtube
Modelo genérico de neurona artificial
De acuerdo con la descripción del grupo PDP (Parallel Distributed Processing Research Group, de la Universidad de California en San Diego) [Rumelhart 86a, McClelland 86], una neurona artificial es un dispositivo simple de cálculo que, a partir de un vector de entrada procedente del exterior o de otras neuronas, proporciona una única respuesta o salida.
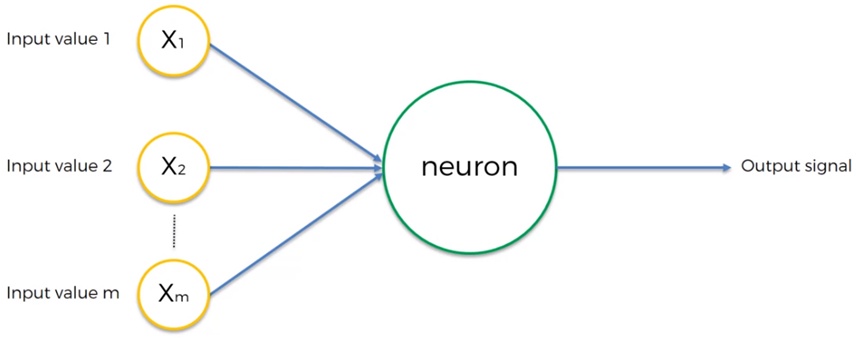
Las entradas constituyen las variables independientes X1, X2, … Xm y la salida Y es la variable dependiente, la cual puede ser un valor continuo, un valor binario, o un valor categórico.
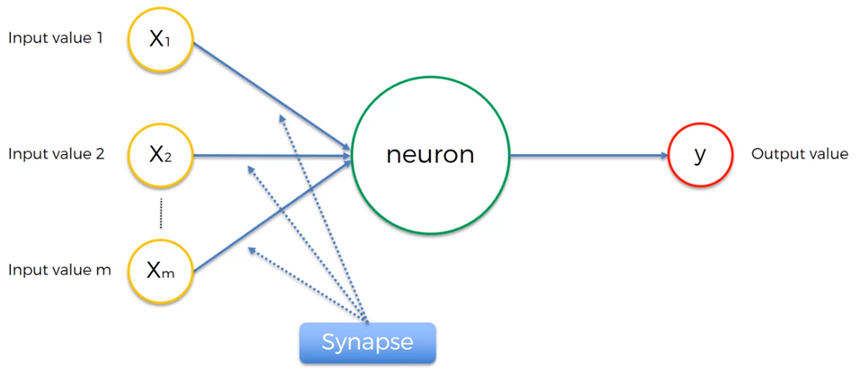
La sinapsis se da a través de los pesos sinápticos que representan la intensidad de interacción de las entradas. La salida en la neurona es la variable dependiente que puede tener valores continuos, binarios o categóricos.
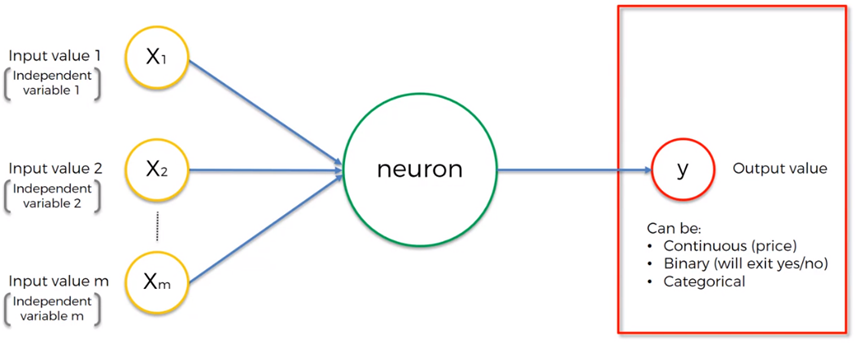
La sinapsis se lleva a cabo con la excitación de las entradas de la neurona que son modificadas por los pesos comúnmente llamados, pesos sinápticos. Esto implica que cada una de las entradas es multiplicada por su peso correspondiente como primer paso en la conformación de una salida.
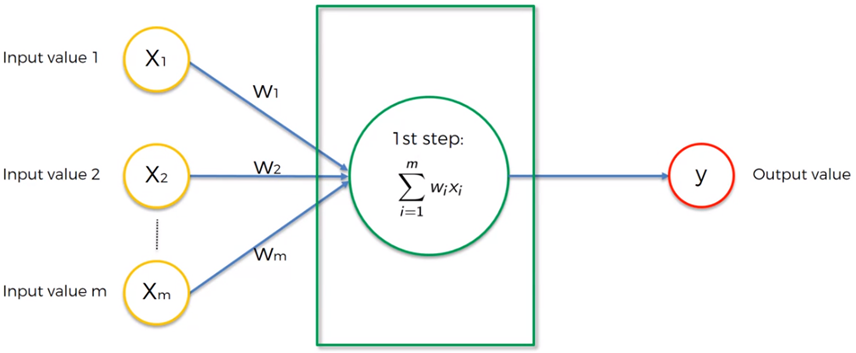
La salida producida en una neurona viene dada por tres funciones:
- Función de Propagación. También llamada función de excitación la cual consiste en la suma de los valores de cada entrada multiplicada por el peso de sus interconexiones. Si el peso es positivo, la conexión es excitadora y si es negativo, la conexión es inhibidora.
- Función de Activación. Si existe, modifica a la función de propagación de acuerdo con un objetivo, si no existe, la salida es la misma función de propagación.
- Función de Transferencia. Se aplica al valor devuelto por la función de activación para acotar la salida de la neurona, por lo que se utiliza para dar una interpretación a dicha salida. Por ejemplo, la función sigmoidal se utiliza para obtener valores en el intervalo de 0 a 1, si se desea obtener valores en el intervalo de -1 a 1, comúnmente se utiliza la función tangente hiperbólica.
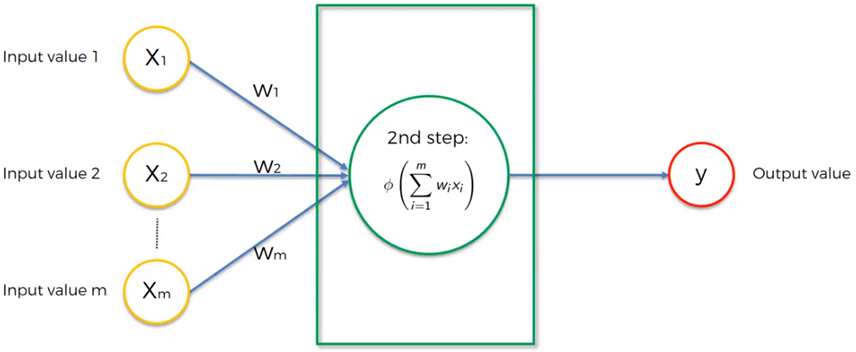
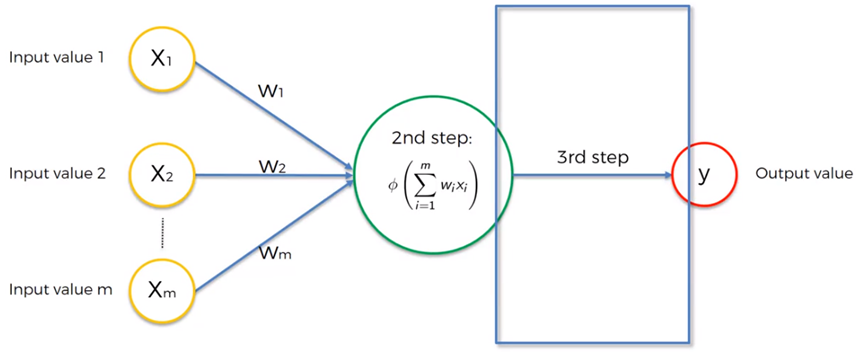
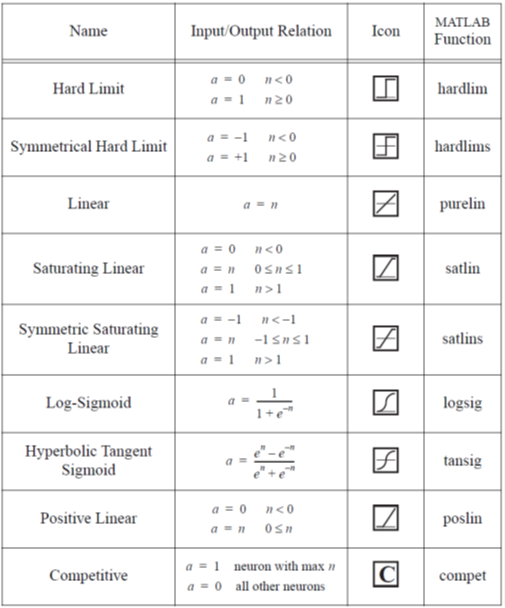
Las funciones de transferencia o activación más comunes se muestran en la siguiente tabla:
El modelo de red neuronal se inspira en la operación del sistema biológico en el sentido de incorporar un conjunto de entradas y proporcionar cierta respuesta, que se propaga por el axón para conformar una salida o la entrada a otras neuronas, constituyendo así una red de neuronas que colaboran entre sí, para un objetivo común.
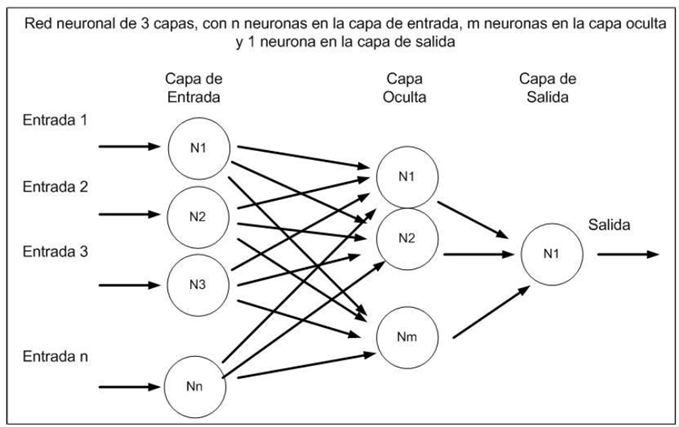
Una red neuronal parte del conjunto de datos de entrada con el objetivo de hacer que la red aprenda automáticamente las propiedades deseadas.
El proceso por el cual los parámetros de la red se adecuan a la resolución de cada problema se denomina entrenamiento neuronal.
Los parámetros de la red los constituyen los pesos sinápticos y el bias o umbral.
En la arquitectura de una red neuronal cada capa puede utilizar una función de activación o transferencia distinta:
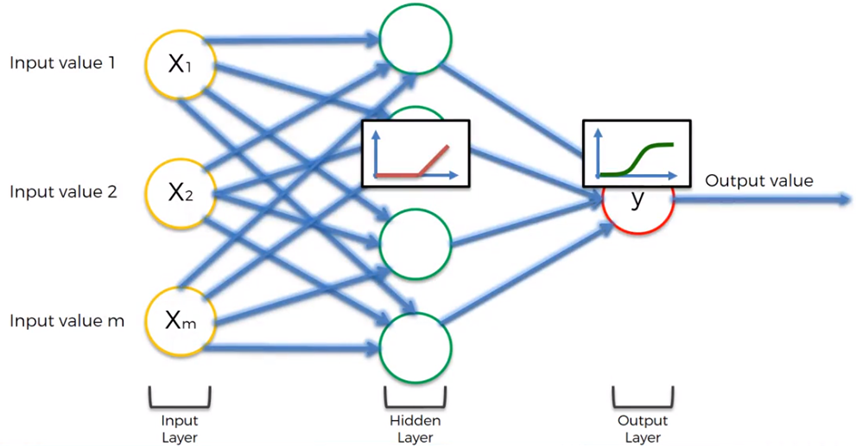
Ejemplo sencillo de aplicación

Estimar el precio de una propiedad basados en datos como el tamaño o área en metros cuadrados o pies cuadrados, número de habitaciones, distancia en metros o millas al centro de la ciudad y edad (tiempo de haber sido construida).
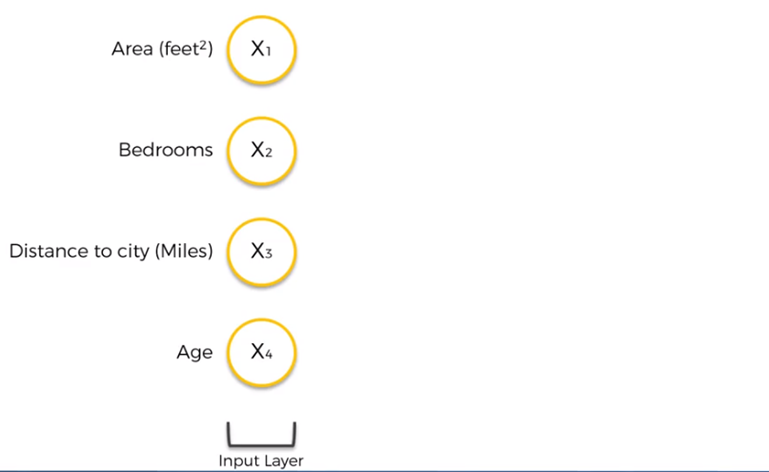
Los datos que describen el valor de la propiedad se constituyen como las variables independientes de la entrada a la red neuronal.
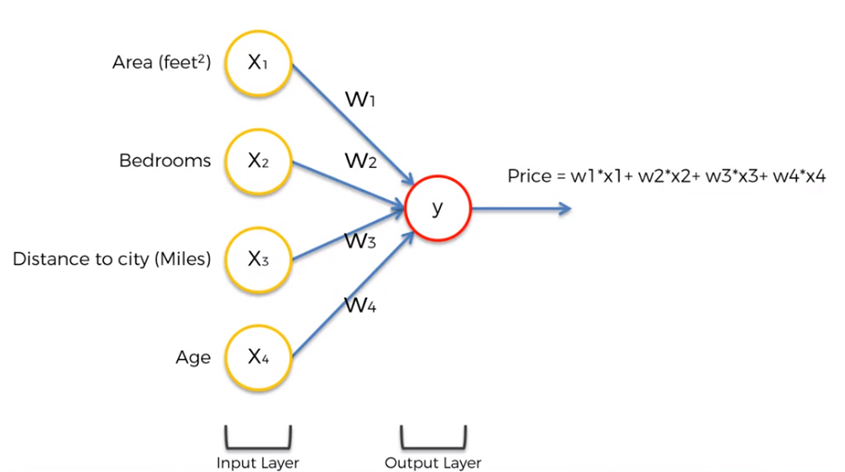
Sin embargo, el problema de la estimación del precio, podría no ser un problema lineal y podría requerir una capa oculta.
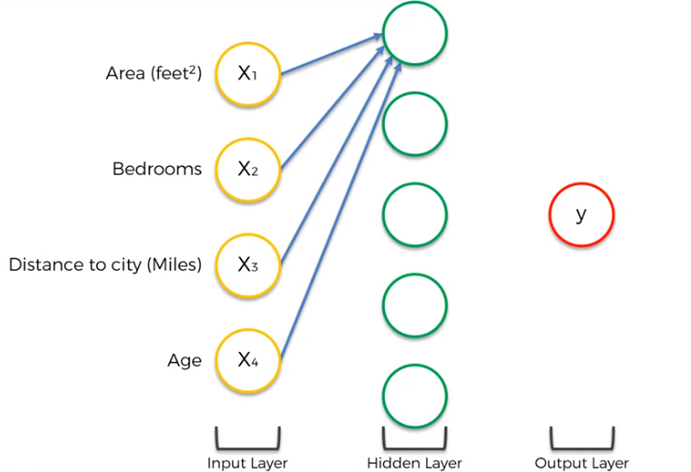
Por lo que cada entrada, o neurona de la capa de entrada, deberá conectarse a cada neurona de la capa oculta.
Si todas las variables de entrada son significativas para las neuronas de la capa oculta, todas las entradas contribuyen con su peso en cada una de las neuronas de la capa oculta. Sino es así, algunas entradas podrían quedar anuladas para una o más neuronas de la capa oculta y esto se lleva a cabo utilizando el valor de los pesos, es decir, el peso se vuelve cero, para aquellas variables que no tienen significancia para algunas neuronas.
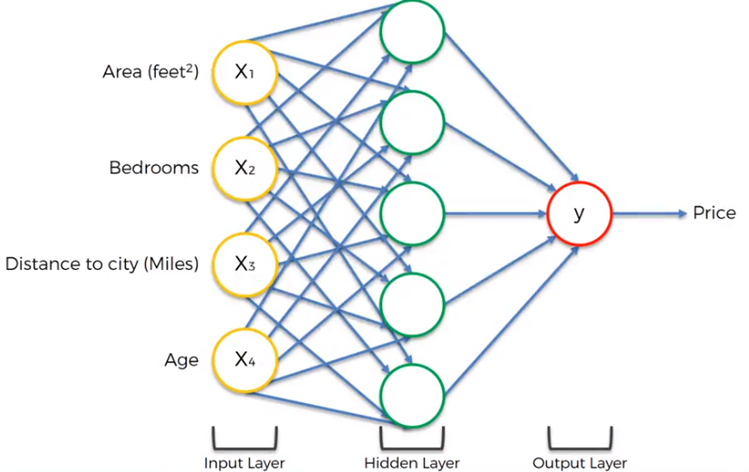
Aprendizaje de una red neuronal
Durante el entrenamiento de la red neuronal, los pesos se modifican de manera tal que la conducta entrada/salida se adecúe con el ambiente que produce las entradas.
Una regla de aprendizaje es un procedimiento para modificar los pesos y los bías de una red. Este procedimiento también se conoce como el algoritmo de entrenamiento.
El objetivo de las reglas de aprendizaje es entrenar a la red para desempeñar algunas tareas y dichas reglas de aprendizaje se clasifican en tres categorías generales:
- Aprendizaje Supervisado. Se proporcionan a la red un conjunto de ejemplo (el conjunto de entrenamiento), para indicarle el comportamiento adecuado de la red. Este conjunto contiene los valores de entrada y las salidas o targets esperados.
- Aprendizaje graduado o reforzado. Este tipo de aprendizaje es similar al supervisado, pero en lugar de proporcionarle las salidas correctas a cada entrada, sólo recibe un score o valor de recompensa, que es una medida del desempeño de la red sobre algunas secuencias de entrada en forma de retroalimentación.
- Aprendizaje no supervisado. En este tipo de aprendizaje, los pesos y los bias se ajustan en respuesta únicamente de las entradas. No hay salidas correctas o targets disponibles. En este tipo de algoritmo se ejecuta algún tipo de operación de agrupamiento o clustering. Aprenden para categorizar los patrones de entrada dentro de un grupo finito de clases.
En el siguiente post hablaremos sobre el algoritmo de entrenamiento para redes neuronales basado en la propagación hacia atrás o back propagation y el gradiente decreciente.