Diseño de Bases de Datos – Parte 3
En la segunda parte del artículo finalizamos con la transformación al modelo relacional, es decir, diseñando las tablas para la base de datos. Dichas tablas se obtivieron en base al modelo entidad-relación y de acuerdo con las reglas de transformación descritas en el artículo anterior.
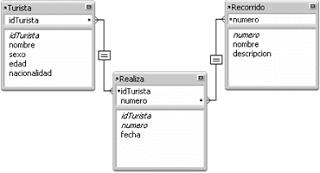
Ahora necesitamos analizar las dependencias que existen entre los atributos o campos de las tablas y de esta forma poder normalizar dichas tablas.
La normalización implica tratar de eliminar al máximo la redundancia de datos que pudiera presentarse al construir las tablas ya transformadas y empezar a almacenar datos en ellas. Algunos grados de redundancia tendrán que ser aceptados en la mayoría de las bases de datos dependiendo de la funcionalidad de la aplicación, la semántica de los datos y las restricciones de usuario.
El tema de la normalización es un poco más complejo y el objetivo de este artículo no es aburrir incursionando en los detalles técnicos, por lo que trataremos de explicarlo de una forma sencilla y clara.
Dada la sencillez de nuestro ejemplo, al llevar a cabo la transformación al modelo relacional, las tablas resultantes se obtuvieron dentro de la segunda y tercera forma normal y esto es debido a las dependencias entre atributos o campos.
Entre los campos de una tabla pueden existir dependencias de varios tipos. Las dependencias son propiedades inherentes al contenido semántico de los datos, formando parte de las restricciones de usuario del modelo relacional.
Existen distintos tipos de dependencias: funcionales, multivaluadas, jerárquicas y en combinación.
Dependencias funcionales
Dada tabla R formada por los campos A, B Y C, representandola de la forma R(A, B, C). Si B depende funcionalmente de A (entonces A implica o determina a B), si para cada valor de A solamente existe un único valor posible para B.
Notación: A -> B
ejemplo: Para la tabla Recorrido, una dependencia funcional existe entre el campo número y el campo nombre:
numero -> nombre
Si además se cumpliera que no pueden existir dos recorridos con el mismo nombre, esto implicaría que el nombre también puede actual como clave de la tabla Recorrido y por lo tanto también derermina funcionalmente a número:
numero <-> nombre
Dependencias multivaluadas
De la tabla R(A, B, C), A multidetermina a B si para cada valor de A existe un conjunto bien definido de valores posibles en B, con independencia del resto de los campos de la tabla.
Notación: A ->-> B
ejemplo: Si en la tabla turista también quisieramos guardar el telefono de los turistas y que algunos de ellos indicaran más de un número: celular, casa, oficina, etc. La dependencia multivaluada estaría dada por:
nombre ->-> teléfono
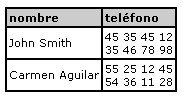
Para cada persona tenemos varios números telefónicos.
Formas normales
Existen seis niveles de normalización de una tabla. Una tabla se encuentra en uno u otro grado de normalización si cumple una serie de propiedades (restricciones) que se explicarán a continuación.
Las tres primeras formas normales las definió Codd y se basan en las dependencias funcionales que existen entre los campos de la tabla. Posteriormente, y basándose en las dependencias multivaluadas y en combinación se definieron dos niveles más de normalización, la 4a y la 5a respectivamente.
Entre la tercera y la cuarta se definió una que se conoce como la forma normal de Boyce-Codd (FNBC) la cual re-define a la 3ra forma normal debido a algunas anomalías encontradas.
De esta forma las tablas en 1a forma normal tienen más redundancia de datos que los niveles superiores y por lo tanto, más anomalías de actualización de datos. La 5a forma normal es el grado de normalización máximo que se puede alcanzar para una tabla.
Primera forma normal
Se dice que una tabla se encuentra en la 1a forma normal cuando cada campo sólo toma un valor del dominio simple subyacente. Es decir que no existen grupos repetitivos.
Un ejemplo lo podemos mostrar con las tablas siguientes, la primer tabla no cumple la restricción de la primer forma normal, sin embargo la segunda si la cumple.
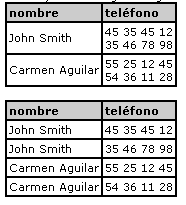
La primera forma normal es una restricción inherente al modelo relacional, por lo que su cumplimiento es obligatorio para todas las tablas.
Segunda forma normal
Se dice que una tabla se encuentra en la segunda forma normal si:
- Se encuentra en la 1er forma normal
- Cada campo que no forma parte de la clave primaria tiene dependencia funcional completa respecto de alguna de sus claves.
Por ejemplo: Turista(idTurista, nombre, nacionalidad) donde la clave primaria es idTurista, existe:
nombre -> nacionalidad
Por lo tanto la tabla Turista con esos campos se encuentra en la segunda forma normal.
Tercera forma normal
Se dice que la tabla se encuentra en la 3a forma normal si:
- Se encuentra en la segunda forma normal
- No existe ningun campo que no forma parte de la clave primaria que dependa transitivamente de alguna clave de la tabla.
Por ejemplo: R(A,B,C) si B -> C R se encuentra en la 2a forma normal, ya que no existe dependencia transitiva de B o C con respecto de A
Análisis
El objetivo del análisis es llevar a cabo un proceso de descomposición por medio de proyecciones sucesivas para obtener, de una tabla, una serie de tablas resultantes, las cuales deben cumplir con la conservación de la información (campos y registros), de las dependencias y que exista mínima redundancia de datos.
De esta forma las n tablas resultantes serán equivalentes a la tabla inicial y tendrán menor redundancia de datos debido a que se encuentran en un nivel de normalización mayor.
Dado que la normalización parece un tema complicado, nos podemos beneficiar ampliamente al entender los conceptos mas elementales de la normalizción.
Una de las formas más fáciles de entender esto, es pensar en nuestras tablas como hojas de cálculo. Por ejemplo para el caso de los teléfonos de los turistas, si agregaremos un campo a la tabla por cada numero telefónico que podríamos capturar para un turista tendríamos algo así:
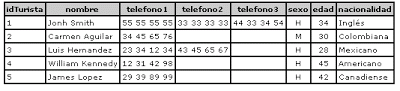
Algunos turistas turistas tienen uno, dos o tres números, no todos tienen los tres números para los cuales tenemos capacidad en la tabla.
Así como hemos mencionado que el objetivo de la normalización es eliminar la redundancia de datos, también lo es eliminar el número de celdas vacías.
El darnos cuenta de que la tabla turista tiene un conjunto fijo de campos (nombre, sexo, edad, nacionalidad) y un conjunto variable de campos (telefono1, telefono2, telefono3), nos da una idea de como dividir los datos en múltiples tablas que estarán relacionadas entre sí.
Cuando hablamos del proceso de descomposición para obtener n tablas resultantes, lo vemos en el ejemplo de los teléfonos y el proceso se describe con la siguiente figura:
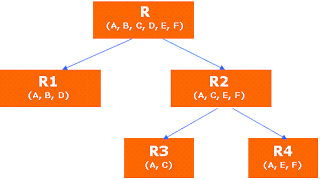
Al aplicar las reglas de normalización a la tabla original R, esta la descomponemos en dos tablas R1 y R2, después, dada la redundancia de R2, le aplicamos las reglas y la descomponemos en R3 y R4. Todas las tablas resultantes: R1, R2, R3, y R4 conservan el atributo A, que es la clave primaria y con la cual estableceremos la relación entre ellas, sin embargo para cada tabla resultante, la clave primaria será una combinación de entre la clave primaria de la tabla original y algún otro campo de cada tabla resultante, dependiendo de las restricciones.
Si aplicamos la regla de la primer forma normal para la tabla de datos del ejemplo, la cual nos indica separar los grupos repetitivos. En este caso el grupo repetitivo es el conjunto de campos para teléfono, los cuales dependen del id del turista, por lo que los separamos juntos.
Separando en dos grupos los campos tendríamos:
1er Grupo (idTurista, nombre, sexo, edad, nacionalidad)
2o Grupo(idTurista, telefono1, telefono2, telefono3)
Ahora para la segunda forma normal, en esta analizamos sólo aquellos grupos que tengan claves combinadas, dado que no hay claves combinadas, ignoramos este paso.
Para la tercera forma normal examinamos las interdependencias entre campos no claves.
Todos los campos o atributos en cada grupo que no sean claves, deben ser examinados para verificar que no existan interdependencias entre ellos. Si se encuentran algunas, tales dependencias deben ser separadas en distintos grupos cuya clave debe ser el campo del cual son dependientes, dejando este campo clave también en el grupo original.
Para el primer grupo analizamos que nombre, sexo, edad y nacionalidad son dependientes de idTurista y no hay interdependencia entre ellos, por lo tanto, ingnoramos al primer grupo.
En el segundo grupo sucede lo mismo, cada campo teléfono es dependiente del idTurista. Pero ahora no todos los turistas tendrán tres teléfonos, por lo que modificamos el segundo grupo y dejamos que cada registro identifique un teléfono único para cada turista, de esta forma el segundo grupo quedará:
2o Grupo (idTurista, telefono)
En el hacemos que la clave primaria y única sea la combinación de ambos campos, es decir, la clave primaria estará formada por idTurista y teléfono. Así podremos evitar también que se capture dos veces el mismo número para el mismo turista, pero podemos tener el mismo número para turistas distintos.
Ahora bien, sabemos que para el campo sexo, sólo pueden existir dos valores (H o M), por lo que podremos utilizar una lista de valores para este campo y evitar errores en la captura del mismo.
Para el caso del campo nacionalidad, la cantidad de valores que se pueden tener es grande, sin embargo para evitar errores en la captura con los posibles datos podríamos separarlo de grupo 1 y crear un nuevo grupo, al cual le tendremos que asignar una clave única:
3er grupo (idNacionalidad, nacionalidad)
El primer grupo quedaría modificado de la siguiente forma:
1er Grupo (idTurista, nombre, sexo, edad, idNacionalidad)
Con ello podríamos crear una lista de valores para nacionalidad y evitar errores en la captura.
Dado los pocos campos que tenemos en las tablas Recorrido y Realiza, no existen independencias o dependencia funcionales y multivaluadas en estas tablas, por lo que no hay necesidad de llevar a cabo una normalización adicional, dichas tablas se encuentran en la 3er forma normal.
Finalmente las tablas a construir en la base de datos son las siguientes:
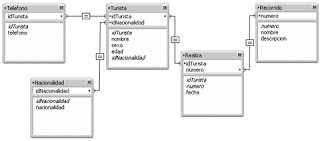
Estas ya son las tablas normalizadas hasta la tercer forma normal que se construiran en la base de datos. Para ello el sigueinte paso es analizar los tipos de datos que se requieren para cada uno de los campos.
En la cuarta y última parte de este artículo hablaremos sobre los detalles para la construcción de estas tablas, los tipos de datos para los campos, restricciones y validaciones, así como las cosideraciones necesarias para la creación de presentaciones (layouts) para la aplicación: captura, consulta, reportes, etc.