
Clasificación con Árboles de Decisión
Los árboles CART (Classification and Regression Tree) constituyen árboles de decisión para problemas de clasificación o de regresión. En el artículo anterior: Árboles de Regresión usando Python te explico los tipos de árboles y el algoritmo para la regresión, en es nuevo artículo hablaremos sobre el uso de los árboles para clasificación.
Los árboles CART fueron introducidos en 1984 y el algoritmo se caracteriza por el despliegue de una serie de preguntas y respuestas para determinar cual será la siguiente pregunta. Los principales componentes de estos árboles son:
- Las reglas para determinar la división de los datos para cada nodo
- Las reglas para determinar donde termina una rama
- Predicción del valor objetivo en cada nodo terminal
Las principales ventajas de los árboles CART son:
- Es un modelo no paramétrico por lo que no depende del tipo de distribución a la que pertenecen los datos.
- No son directamente impactados por valores fuera de rango o valores atípicos.
- Incorpora tanto datos de entrenamiento como de prueba y una validación cruzada para evaluar la bondad del ajuste
Con todo esto, un árbol de decisión es una representación gráfica de todas las posibles soluciones para ayudar a tomar una decisión. La intuición básica detrás de este tipo de árboles es dividir un gran conjunto de datos en subconjuntos más pequeños bajo ciertas reglas hasta obtener un conjunto de datos lo bastante pequeño para establecer una simple etiqueta.
Cada característica que permite hacer la división se denota por un nodo del árbol mientras que las ramas representan las posibles decisiones. El resultado de la decisión, está indicado en un nodo hoja sin ramas.
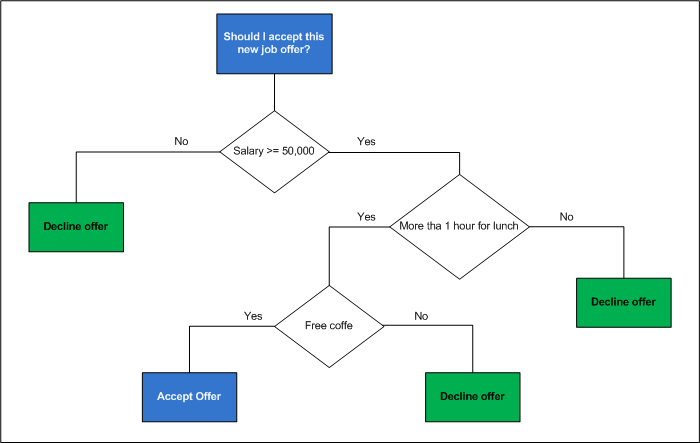
En la imagen anterior vemos un modelo de árbol de decisión en donde negociamos con un problema de clasificación binaria, aunque en muchos casos podemos tener árboles de decisión para múltiples clases. En el ejemplo anterior tenemos sólo dos opciones de decisión, aceptar o declinar la oferta de trabajo. La rama a seleccionar es aquella que nos proporciona la mayor cantidad de información para disminuir el grado de aleatoriedad en nuestra decisión.
Finalmente, la división de los datos se hace con la intención de minimizar la entropía y maximizar los grupos de datos.
Árboles de Decisión con Python
Para el ejemplo, utilizamos un archivo de datos con información sobre los clientes que han comprado o no en línea. Si compro el valor de la variable dependiente es 1 y si no compro, el valor es 0. Los datos en la variable independientes son el género, la edad y el salario estimado.
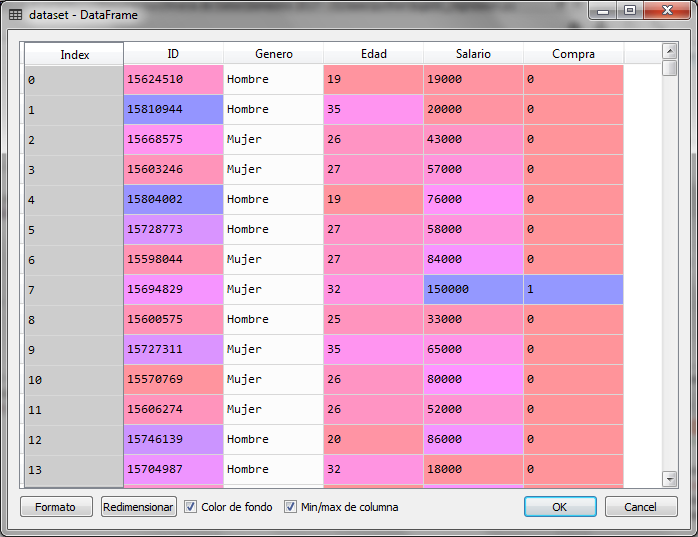
Utilizaremos la edad y el salario estimado para crear un árbol de clasificación con las etiquetas de compró (1) o no compró (0) y con ello poder clasificar registros nuevos. Para ello creamos el árbol con un conjunto de datos que llamamos, el conjunto de entrenamiento.
# Clasifiación con Árboles de Decisión # Importacion de librerias import numpy as np import matplotlib.pyplot as plt import pandas as pd # Importacion del dataset dataset = pd.read_csv('Compras_en_Linea.csv') X = dataset.iloc[:, [2, 3]].values y = dataset.iloc[:, 4].values # Division del conjunto de datos en datos de entrenamiento # y datos de prueba from sklearn.cross_validation import train_test_split X_train, X_test, y_train, y_test = train_test_split(X, y, test_size = 0.25, random_state = 0) # Ajuste de escalas from sklearn.preprocessing import StandardScaler sc = StandardScaler() X_train = sc.fit_transform(X_train) X_test = sc.transform(X_test) # Creamos el Árbol de Decisión para Classificación y lo entrenamos from sklearn.tree import DecisionTreeClassifier classifier = DecisionTreeClassifier(criterion = 'entropy', random_state = 0) classifier.fit(X_train, y_train)
Al ejecutar este fragmento de código estamos cargando el conjunto de datos con 400 registros de clientes de los cuales, el 25% se utilizará para probar el modelo y el 75% (300 registros) para el entrenamiento o crear el árbol bajo los criterios de la edad y el salario estimado (columnas 2 y 3).
import pydotplus from sklearn.tree import export_graphviz dot_data = export_graphviz(classifier, out_file=None, filled=True, feature_names=['Edad', 'Salario']) graph = pydotplus.graph_from_dot_data(dot_data) graph.write_pdf('tree.pdf')
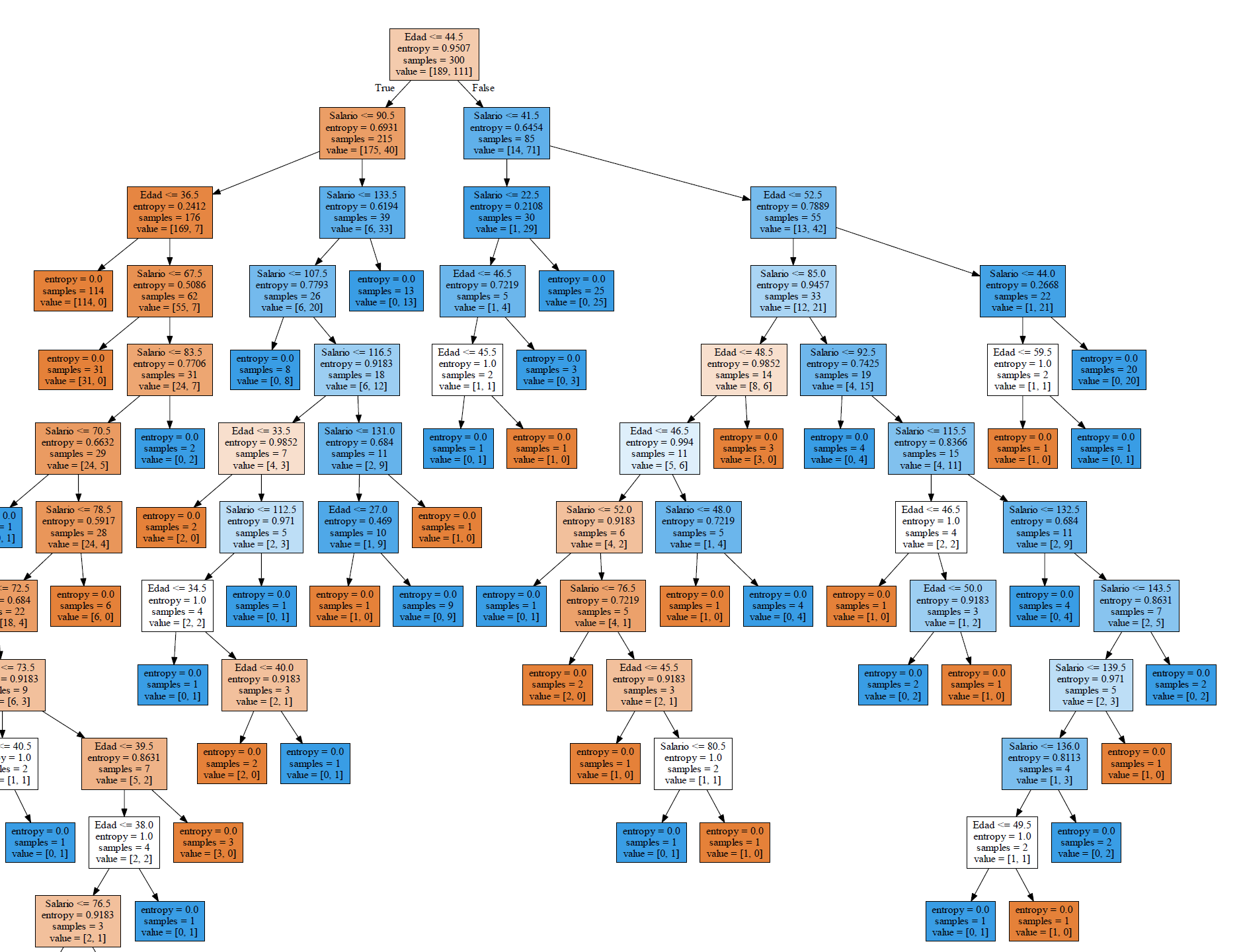
Dado el tamaño del conjunto de datos de entrenamiento, el árbol es demasiado grande, pero al ver la imagen con detalle, observamos que cada hoja o nodo final tiene un valor de entropía igual a cero. En el mismo nodo nos muestra la cantidad de registros que cumplen el criterio.
Si ahora ajustamos el árbol para los 100 registros del conjunto de pruebas, el gráfico resultante es más pequeño y se puede apreciar mejor.
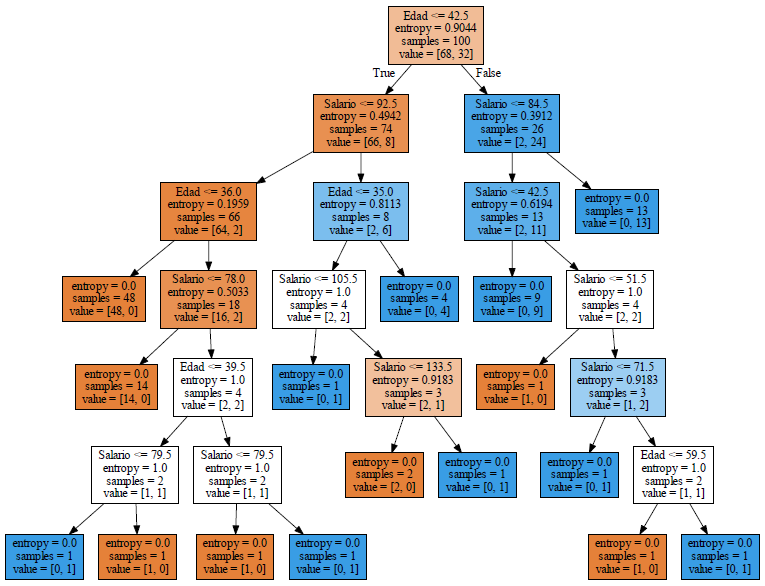
En el nodo final ubicado del lado derecho en el tercer nivel, dice entropía = 0, muestras = 13 y value = [0, 13] es un nodo de color azul que indica que los clientes de edad mayor a 42.5 y salario mayor a 84.5 si compran.
Ahora si hacemos la predicción para el conjunto de pruebas y checmos la matriz de confusión, tenemos:
# Predicting the Test set results y_pred = classifier.predict(X_test) # Making the Confusion Matrix from sklearn.metrics import confusion_matrix cm = confusion_matrix(y_test, y_pred)
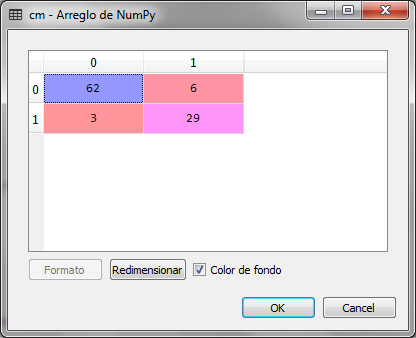
Observamos que de 100 registros del conjunto de pruebas, hay 9 errores, es decir, 3 elementos que debieron clasificarse con 1 se clasificaron con 0, estos representan los falsos positivos. 6 registros se clasificaron con 1 y debieron clasificarse con 0, estos últimos representan los falsos negativos.
Esto implica que la precisión del modelo es del 0.91, es decir 91% mucho mejor a la que resultó con el mismo conjunto de pruebas, la regresión logística del artículo anterior.
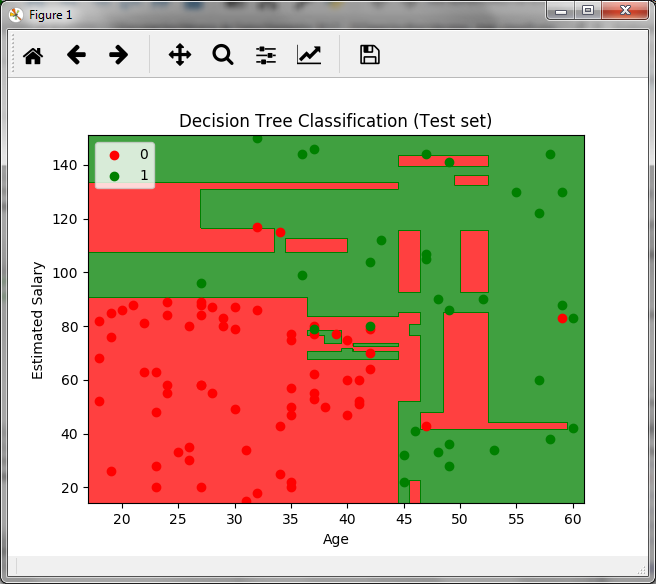
La gráfica anterior se crea para el conjunto de pruebas y en ella vemos las fronteras de decisión para los datos, la zona verde es para los clientes que si compran y la zona roja para aquellos que no.
Hello, that’s an interesting topic to discuss. Agree with an innovation that you share through this article. Could I add some points?
Sure, Go ahead
Hola… Muy buen artículo. Desde dónde puedo descargar los datasets que mencionan???
Hola Jaime,
Perdón por la tardanza en responder.
Te dejo la liga de una carpeta donde están los datasets
https://drive.google.com/drive/folders/1Jdg2ttdM8pvSdC2ndd5tS5rPI37uTC_t?usp=sharing