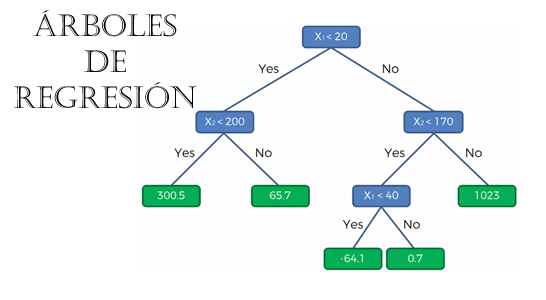
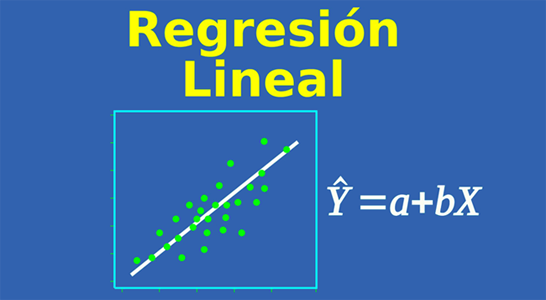
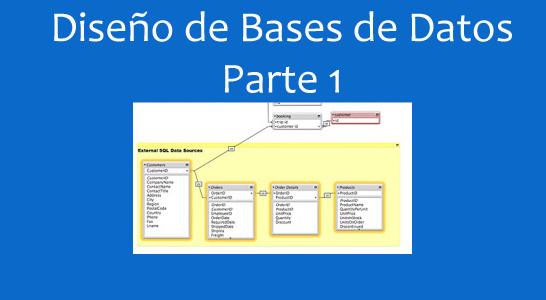
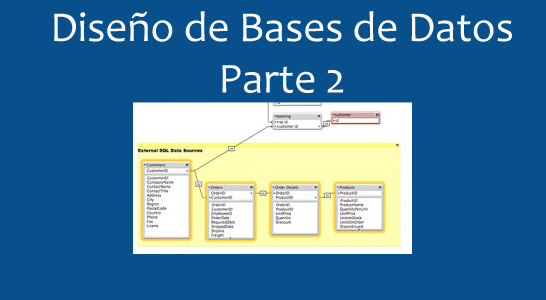
En minería de datos, machine learning y/o ciencia de datos, en lo que se refiere al análisis con árboles, existen dos enfoques principales: los árboles de decisión y los árboles de regresión. En ambos casos los árboles constituyen métodos predictivos de segmentación, conocidos como árboles de clasificación. Son particiones secuenciales del conjunto de datos realizadas para maximizar las diferencias de la variable dependiente dado que se realiza una división de los casos en grupos. A través de diferentes índices y procedimientos estadísticos se determina la división más discriminante de entre los criterios seleccionados, aquella que permite diferenciar mejor a los distintos grupos del criterio base, con lo que se obtiene así, una primera segmentación. A partir de esa primera segmentación, se realizan nuevas segmentaciones de cada uno los segmentos resultantes y así sucesivamente hasta que el proceso finaliza con alguna norma estadística.